7 min to read
Analyser des sites de phishing
Détection de sites de phishing.
Contextualisation
Les informations données ci-dessous sont issues de mon expérience personnelle. Elles n’ont pas vocation à être des vérités générales, mais elles sont là pour aider et proposer des pistes à des personnes qui se demanderaient comment il est possible de détecter des sites de phishing visant une organisation particulière.
On s’intéresse ici à un ensemble d’URL que l’on a en notre possession. On suspecte certaines de ces URL d’être des sites de phishing visant une URL connue. Par exemple, l’URL de ce blog (vu la quantité d’informations dessus il n’est peu être pas très pertinent de le recopier mais bon, sait on jamais). En pratique, ce sera plutôt la page d’authentification d’un service (assurance, banque, compte client…) ou vers une fausse page de facturation afin d’extirper les coordonnées de carte bancaire ou les identifiants de connexions.
On suppose ici que l’on est propriétaire du site dont on cherche à identifier les copies, alors cet ensemble d’URLs peut être récupéré en regardant les logs du site.
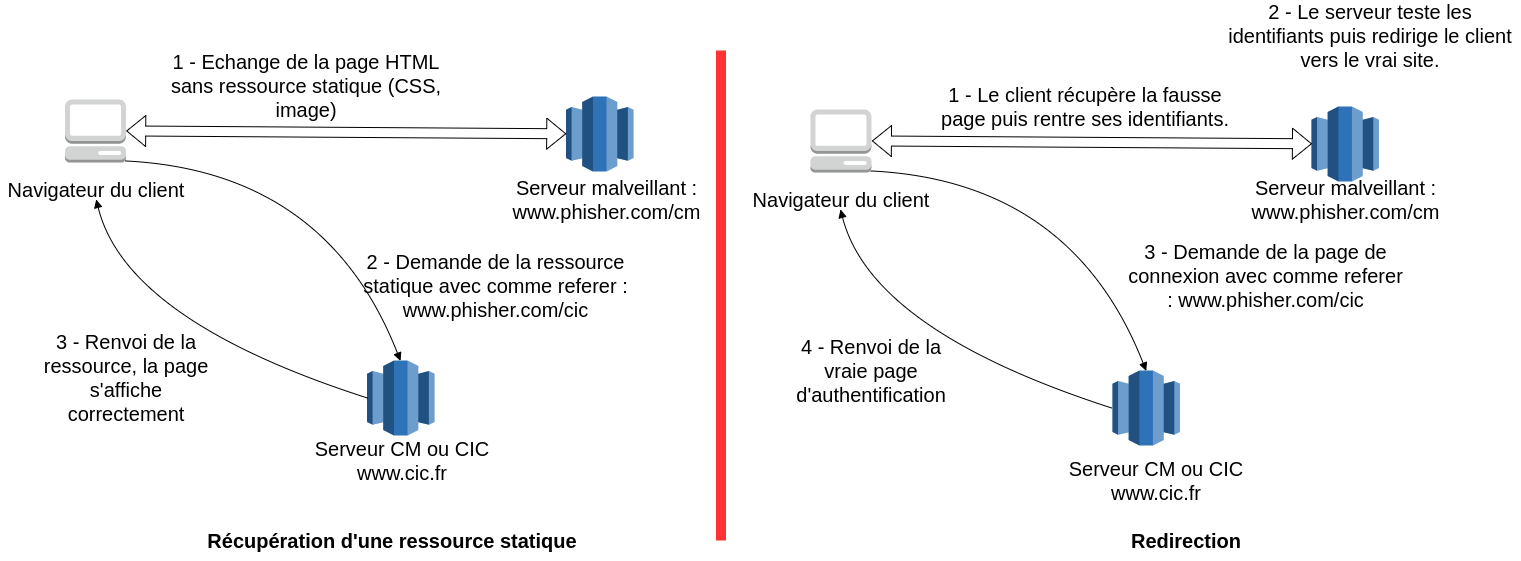
En effet, un site de phishing va souvent chercher à imiter le site qu’il vise. Pour ce faire il est possible qu’il aille chercher des ressources statiques sur le serveur légitime, ou qu’il redirige vers le site qu’il copie une fois que le client a saisi ses informations. Voici un schéma illustrant la récupération possible de l’URL d’un site de phishing.
Une fois la récupération des referers faite, il faut les analyser, il est possible qu’une grande partie de ceux-ci soit légitime. Le but de cet article est de proposer des méthodologies d’analyses pour permettre de trancher sur la nature de chaque site potentiellement suspect.
Considération sur les sites de phishing
Les utilisateurs sont de plus en plus avertis sur les risques du phishing et ont tendance à vérifier (parfois..) l’URL du site sur lequel ils se trouvent avant de rentrer leurs informations. Un site pirate a donc intérêt à avoir une URL proche de celle du site copié. Souvent un site de phishing sera réalisé par l’intermédiaire d’une copie du code HTML de la page et il est intéressant de chercher les points communs entre site légitime et site suspect. Si ces deux premières méthodes n’aboutissent pas pour différentes raisons, il est possible d’envisager une comparaison d’image car le site de phishing.
Un kit de phishing est un programme qui est placé sur différents sites, il est important d’être capable de détecter des kits passés, mais aussi d’être en avance de phase et de pouvoir identifier de nouveaux kits par l’intermédiaires de nouveaux sites.
Analyse
Analyse de l’URL
Pour analyser l’URL d’un site plusieurs points peuvent être considérés. Le premier est de regarder le nom de domaine de l’URL à analyser. Il se peut que le nom de domaine soit celui d’une régie publicitaire, ou d’un site connu depuis lequel il est logique d’avoir des redirections vers notre site. Ces noms de domaines peuvent être mis dans une whitelist pour faire un tri rapide. Il se peut que dans les URLs des sites malicieux des motifs reviennent de façon récurrente. Il est envisageable de blacklister les URLs contenant ces motifs et de les considérer comme étant suspecte. Par exemple, dans le cas d’un site d’assurance, des referers contenant le pattern : “regler_assurances_en_lignes.php” pourrait être considéré comme suspect. Il est possible (pour des raisons que je ne comprends pas bien) que certains sites de phishing recopient leur contenu lors de l’arrivé d’un nouvel utilisateur dans un répertoire au nom aléatoire. La recherche de patterns aléatoires comme 32 caractères alphanumériques de suite précédés et suivis d’un “/” peut être utile.
Le désavantage de cette approche est qu’elle permet uniquement de détecter des kits de phishing déja connus.
Une autre approche naturelle est d’introduire une notion de distance entre des chaînes de caractères. Plusieurs distances comme celle de Levenshtein ou de Needleman existent. La première est compte le nombre d’insertion, de suppression et de transformation nécessaire pour passer d’une chaîne de caractère à une autre, la deuxième sert en biologie pour la comparaison de séquence peptidique et introduit des coefficients en fonction des opérations réalisées. Ce type de distance, appliquée à l’URL complète ou aux noms de domaine permet de repérer le typosquatting.
Prenons un exemple sur le site OpenPhish : http://information-ameli-moncompte.com/Mon_compte/Services/AmeliAssurance=Valid/assure_somtc=true/63bf3caa432a0d06f0ebce4fcd9be136/connexion_compte/sms2.php
Ici les différentes techniques présentées auraient identifiées différentes parties de l’URL :
- la blacklist de pattern aurait pu servir à identifier le “sms2.php”
- la recherche de hash aurait permis d’identifier le “63bf3caa432a0d06f0ebce4fcd9be136”
- l’analyse par distance textuelle aurait pu permettre de détecter une URL proche du site d’ameli (Assurance maladie)
Analyse du code HTML
L’analyse du code HTML consiste à comparer un certain nombre d’élément de la page que l’on suppose copiée. Pour se faire plusieurs choses sont possibles :
- Comparer la distance des textes ou du HTML des deux pages avec les algorithmes évoqués précédemment.
- Comparer l’adresse de la source des images ou des scripts,
- Comparer le nom, la classe ou autre attribut de certains champs sur la page,
- Vérifier que le nombre d’input possible correspond à celui de la page copiée…
Les possibilités sont nombreuses et il faut faire des choix sur ce que l’on veut comparer. Pour moi, la comparaison des sources de données est une bonne chose, de même que le nommage des champs liés aux informations demandées à la victime du phishing.
Pour faire cette analyse des librairies de traitements du HTML comme BeautifulSoup en python, ou JSoup en JAVA, sont très utiles. Elles permettent des sélections précises de certaines balises, la vérification d’attributs, etc…
Pour se soustraire à cette analyse, certain créateur de kits de phishing utilisent diverses techniques dont il faut se prémunir. On peut citer les suivantes :
- écriture de la page dans une iframe où la source des données est l’HTML de la page en base 64,
- réalisation d’un site de phishing sans copie du code HTML (juste un screenshot du site à copier en image de fond et un formulaire ajouté par dessus).
Analyse d’images
Des outils comme Selenium ou PhantomJS (même si ce dernier n’est plus maintenu) permettent de prendre des captures d’écran de la page visitée. Une analyse sommaire mais efficace consiste à réduire les deux captures d’écran à une dimension plus petite et à faire une distance quadratique entre les deux images. Cette façon de faire possède plusieurs avantages :
- Comparée à d’autres méthodes d’analyses d’images, elle est simple et assez rapide à implémenter,
- Permet de s’adapter à toutes les tailles de screenshot.
- Permet de détecter les sites une fois le chargement de la page terminé
Nouveaux kits de phishing
La découverte de nouveaux kits de phishing peut être l’occasion d’adapter son outil à de nouvelles façons de faire. Par exemple, pour le cas présenté plus haut d’écriture du code source dans une iframe, il est possible de devoir adapter son outil à la recherche d’éléments dans le code source de l’iframe.
Pour recenser et découvrir de nouveaux sites et pouvoir observer les modes de fonctionnement de ceux ci, il est judicieux de faire un tour sur OpenPhish, et de se rendre volontairement sur des sites de Phishing. En effet, il n’est pas rare qu’à la racine du répertoire contenant le kit, le pirate laisse l’archive de son kit. De cette manière, il est possible d’observer de nouveaux comportements et de comprendre mieux le processus de récupération des données clients.
Voici une liste de choses que j’ai pu observer :
- Très souvent les kits de phishing sont en PHP, souvent déposés sur des serveurs contenant des CMS vulnérables,
- une blacklist d’IPs est souvent présente dans le kit, avec parfois des informations supplémentaires permettant d’identifier des IPs à bloquer,
- les informations récupérées sont souvent transmises par mail, parfois écrites dans des fichiers à la racine du répertoire.
Remarques
Bientôt un outil de détection de sites de phishing reprenant ces grandes lignes devrait être accessible sur GitHub. L’idée est d’illustrer le propos de cet article avec un prototype fonctionnel. Ce ne sera pas un outil extraordinaire mais seulement un code fonctionnel fait pour apprendre.